The Loupe Service's Terrible, Horrible, No Good, Very Bad Day
This has not been a good day. In truth, the problems started yesterday. Yesterday morning we started getting reports from users that Loupe Desktop was prompting them to log in, over and over. Since we’d deployed Loupe 4.0.1 over the weekend which had some new security features (including enforcing authorization on every API call for Loupe Desktop) we suspected this was a simple issue of the original Loupe 4.0 client not knowing it had to submit credentials for all types of requests.
We dutifully pushed folks to upgrade to the latest client and it seemed to resolve the issue but by the time we came in this morning it was clear we had a big problem on our hands: reports from several customers of the same issue, including some running the latest version.
How Not to Do Customer Service
If you do direct customer service one of the biggest challenges is differentiating real, new problems from users not following the instructions you’ve given them. Tell five folks to update to a new version and two will say they did but somehow are still running the old version. We knew Loupe 4.0 Build 3015 had two different issues: It would pester you to re-authenticate over and over and it wouldn’t generate a new token correctly if the server token expired. Since we’ve been running Loupe 4.0.1 internally for months under development without any sign of an issue it seemed overwhelmingly likely that folks were running the old version and somehow it was causing the issue.
Still, even while I was responding to tickets telling folks to verify what version they had and to download the latest build it nagged me that I personally had run that same old version for a few weeks to be sure a problem like this wouldn’t come up. Something wasn’t quite right.
Finally, a user sent us back a screenshot of our own about page proving they had the latest version. It wasn’t the client, so what was going on? I’m embarrassed to say that at that moment it finally hit me to go look at our logs. Ten second later the logs showed something clearly wrong:
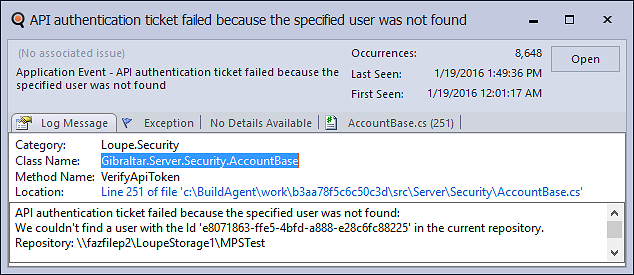
The thing is, the system won’t generate a URL to send a user into a repository they don’t have access to so it should never happen that an authenticated user isn’t present in the repository they’re trying to access. Certainly not thousands of times in twelve hours. The good news is it was very easy for us to look up the user from their GUID in our back end and identify the repository they were trying to access. Reviewing the full log, it was clear that the authentication system was combining a user key and a repository key that weren’t on the same request. One of them was wrong, and the inner safety features of the codebase were blocking what they thought was an attempt to bypass authorization.
What Went Wrong
Here’s the original code with the defect (simplified)
public class LoupeAuthHandler : DelegatingHandler
{
private CentralRepository _centralRepository;
private CentralRepository CentralRepository
{
get
{
return _centralRepository ??
(_centralRepository = ServiceLocator.Current.GetInstance<CentralRepository>());
}
}
protected override async Task<HttpResponseMessage> SendAsync(HttpRequestMessage request, CancellationToken cancellationToken)
{
if (request.Headers.Authorization == null)
{
AlternativeAuthentication(request);
}
return await base.SendAsync(request, cancellationToken);
}
private void AlternativeAuthentication(HttpRequestMessage request)
{
SessionDataRequestAuthType authType;
string authHash;
// user SessionDataModule to check for authentication and let us know what
// it is and the hash from the request, if exists, we can use to authenticate
if (SessionDataModule.GetAuthentication(request, out authType, out authHash))
{
// Only supporting credential authentication as an alternative method at this point in time
if (authType == SessionDataRequestAuthType.Credentials)
{
if (CentralRepository.IsAuthenticated(authHash) == false)
{
Log.Write(LogMessageSeverity.Information, AccountBase.LogCategory,
"Request has invalid credentials so will be considered unauthenticated", "Type: {0}\r\nHas: {1}", authType, authHash);
}
}
}
}
}
Line 32 or 37 had to be where it all went wrong - either we were getting the authHash for a request that wasn’t the current request, or applying it against the wrong central repository. Nothing felt amiss, the code looked a lot like what we’ve done in our controllers. And then it hit us - the lifespan of a Delegating Handler in MVC isn’t the same as a controller. They get shared across many requests, up to the life of the process. Some focused testing later and we proved it. The problem was line 9: we were caching the repository into a member variable and reusing it on future requests, requests that most likely weren’t going to be for the same repository. The fix was simple: Call service locator each time just before line 37 to resolve the right repository for the current thread’s current request.
45 minutes later (long enough for our total build process which runs all our automated tests) and we were pushing the fix into the production cluster. It was 30 hours from the first customer problem report to us deploying the fix.
How’d We Miss That?
In the spirit of Joel Spolsky’s Five Whys, how did we not catch this problem? The defect was added to the system back in October. We’ve been running this internally for three months without running into it. Why?
Looking at our git history it was clear we’d copied code out of our controllers that worked there. This makes sense - the lifespan of a controller is such this caching is fine. That’s why the code was wrong in the first go.
To run into the problem three things have to come together:
- Use Loupe Desktop since it’s related to the alternate way Loupe Desktop provides credentials to the server.
- Access a multi-repository system (like the Loupe Service or our enterprise systems)
- Access new API features from two repositories on the same server without the server restarting.
We have unit tests for this code, but they by design reset state so even though they run in both single and multi-repository modes the very way they isolate state to test the system would prevent them from ever satisfying the third condition. That’s why our unit tests didn’t hit it.
Internally we are always testing Loupe - individual developers run in a mix of multi-repository and single-repository modes so we’ll tend to run into problems that just affect one or the other. We use both Loupe Desktop and the web UI. But, it turns out we never hit all three of the conditions above, mostly because of the last condition. It just doesn’t come up much in testing, so that’s why we didn’t see it in our own dog fooding.
We give preview builds to select customers - a mix of Enterprise (multi-repository) and Standard users. They didn’t run into it because ironically their users tend to have access to all repositories so the defect wouldn’t manifest for them; it would incorrectly just let the request through. That’s why our beta customers didn’t hit it.
We deployed on Saturday and paid close attention to events over the weekend as we rolled out the update to more and more repositories. The system is pretty lightly loaded over Saturday nights (that’s a reason we do updates then) and in particular people don’t tend to run Loupe Desktop over the weekend at all. We didn’t see anything out of normal and our own use didn’t hit the problem because while our production Loupe data does flow through the same servers as everyone else it gets redirected down to our internal cluster which is hooked up to our build system (so it’s almost always a newer version than we’ve deployed). That means it wouldn’t be susceptible to the problem. By the time we started getting reports of the problem we were focused on the very last few changes that we’d done to the code in the last few weeks - notably making a number of the API calls used by Loupe Desktop asynchronous using async/await. This had caused some defects to pop up during testing due to some server items not tracking the current task accurately, such as HttpContext.Current. This pushed us to spend about a day looking in the wrong place for the problem: trying variations of async/await and attempting to reproduce a multi-server threading problem. That’s why it took us a day to focus in on the right area.
Logging to the Rescue
You wouldn’t think we’d need this reminder, but we’ve got our days where we’re just regular folks too. Our logging was essential to provide the hard proof that something we didn’t believe was possible was actually happening. When we found what we thought the problem was and it didn’t make a difference it kept providing the proof we had missed the mark. From when we cracked open the logs to when it was fixed was about three hours. Simply recording the exceptions wouldn’t have worked either - we had to see the lead up to the user getting an access denied, and many systems treat that like a normal event because any production system is going to get a few 401’s now and again.
Having the blow-by-blow details of what the request was doing (we record on average 10 log messages for every API request our web server gets) gave us the hard proof of who it was affecting and where it was going wrong. That’s how you fix a problem in production!
Lets Not Repeat This Problem
We’re committed this year to accelerating the pace of updates to our SaaS platform. At the same time, we have to reduce problems like this because we’ve got more and more folks depending on us to be up and running whenever they need us. There are a few things we can do:
- Create a Fast Ring Loupe Service: Some customers have asked us if we’d let them run the very latest we’ve got and traditionally we’ve only done that for self-hosted folks. We could segregate off a block of customers onto their own cluster so we could update them rapidly which would have been guaranteed to force a problem like this into the light.
- Modify our Internal Testing: You can bet we’ll do some focused multi-repository testing before each release, but would that really catch the defects that are likely to crop up on the future? It’s not clear the juice would be worth the squeeze.
- Verify our Diagnosis with the Logs: We lost a lot of time because I was pretty sure I knew what our customers were experiencing from their description and didn’t double-check that the logs backed up my diagnosis. With what we’ve done in Loupe 4 it would have just added a minute or two for me to get proof. That’s worth doing every time.
Finally, there’s one last thing to do - apologize. From day one, Gibraltar Software has been about being rock solid in everything we do. I fell short of that by a big margin, and I apologize to our customers for that. We’re on it, and we’re going to do better.
Title borrowed from Viorst, Judith “Alexander and the Terrible, Horrible, No Good, Very Bad Day” 1972.