Migrating SQL Server to SQL Azure - The Loupe Service goes Cloud Native
In a previous post we covered how we’re migrating all our services from running on our hardware in collocation facilities to cloud hosting. Pop back there for a rundown on how we see the trade-offs and our progress so far.
The next step in our migration is to convert from our current hybrid scenario where all our VM’s are running in Azure as well as our file storage but all our databases are still hosted in SQL Servers back in our main data center. Previously we’ve set up SQL Server on VM’s in Azure (which we’re using for our largest customer) but it’s not been a very satisfactory experience. In particular, the availability story is poor: Unless you set up a SQL Enterprise Always On configuration (a very expensive and complicated endeavor) you’re going to have unscheduled 30 minute outages whenever Azure feels like updating their host software.
The clear preferred solution is to use SQL Azure: Barring operations errors on Microsoft’s part it is kept operational, patched, and backed up by Microsoft. It’s also fully supported by Loupe Server, at least Standard Edition, so we know we’ve already done the leg work to update Loupe to address any compatibility issues. There are two things we’ve had to address - First, the pricing for SQL Azure has been unaffordable for a database-per-tenant SaaS system. Second, there is basically no migration story from SQL Server to SQL Azure.
The Migration Story
So, that’s a little unfair - there have always been instructions on how to migrate an existing database from SQL Server to SQL Azure. It’s just that they’ve been pretty laughable for non-trivial databases in production. The obvious way to migrate would be to use one of the two techniques that have worked for SQL Server migration for 20 years:
- Make a Backup and Restore it: You can take a backup from nearly any old version of SQL Server and restore it to any other SQL Server same version or later. It’s fast and effective.
- Detatch/Retach: You can detach the database files from the old SQL Server and attach them to the new server as long as you’re within some very broad ranges of versions (going back about a decade at this point).
Unfortunately, and remarkably, this just isn’t possible with SQL Azure. For whatever reason while it’s possible to make SQL 2016 take a backup from SQL 2000 and restore it you just can’t do that with SQL Azure. Instead, every migration approach requires some form of:
- Export Schema from Source
- Export Data from Source
- Correct Schema commands to work on SQL Azure and play into new database.
- Import Data
SQL Azure Migration WizardFortunately, some folks have been diligently working on making the best of a bad situation and created the SQL Database Migration Wizard. You can download the simple .NET application which works with libraries installed by SQL Server’s management tools (so you need to get the version that corresponds to your SSMS installation). It rolls through each of the steps, providing a GUI as it goes
{kind=link}
To speed up the process, the Migration Wizard uses SQL’s binary copy (BCP) tool to export and import data. This is dramatically faster than using TSQL, but has a number of constraints. Fortunately, migrating an existing database with the same schema guarantees these are satisfied.
Optimizing the Migration
Where to Run the Migration Tool
Since we’re moving data between data centers as well as servers that means the data has to go from one server to the computer where the migration is being run and then from that computer to SQL Azure. This creates then an obvious question: should the migration tool be close to the source server or the target server? Which end is more sensitive to latency? From running several test migrations it’s clear that there’s much more back & forth while exporting data than importing. In fact, we found no situation where sending data into SQL Azure was limited by network performance, instead we always hit the DTU limit on SQL Azure.
We also experimented moving the extracted data files over the wide area and then running from there to SQL Azure and found no improvement in performance, even when excluding the time to transfer the files. So, good news - you can run it near the source SQL Server and know you’re getting the best performance you’re going to get.
Scale on Demand For The Win
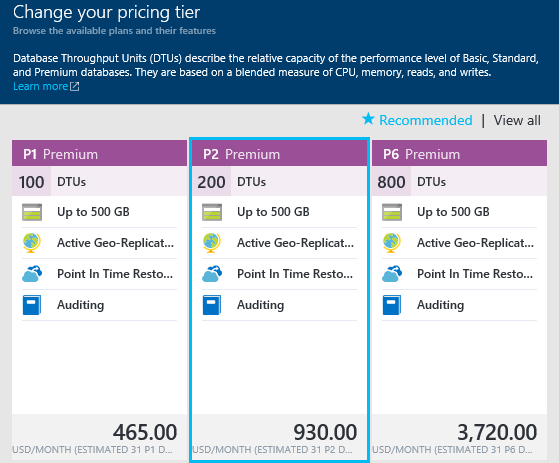
Since the performance if the migration is bound by the SQL Azure DTU limit that means you can speed up larger databases by temporarily giving them a higher performance setting then backing them off later. This is best done when creating the database because while changing down is virtually immediate changing up to a higher performance category can take some time (hours even).
In our scenario we settled on using the Premium 2 setting during the migration and then moved the database into an elastic scale pool once the post-migration cleanup was complete (more on that later!). While the Premium tier is quite expensive, since you’re paying by the hour it really is a small incremental cost and minimized downtime for our customers. Plus, while moving up from Standard to Premium can take a while, downgrades are immediate.
Automating Migrations
We have a lot of database to migrate - one for every tenant on our SaaS. Plus, the migration needs to interface with our systems to put a tenant into maintenance mode, confirm that all activities have completed, create the database, then do the migration, then our custom cleanup and finally bring the tenant back online.
While the SQL Database Migration Wizard doesn’t have a command line interface, it is published with source code which means we were able to create our own command line wrapper. This wrapper let us bypass the UI prompts and meant we just needed to add a final step to confirm the results were good before we finalized the migration. Most folks probably aren’t going to have our scenario of wanting to move so many databases and could just stick with the GUI without issue.
It’s Not Over - Important Post-Migration Cleanup
After moving the first three sample databases (one each for large, medium, and small) and ran some tests, we found some baffling results. In our case, the medium database had unacceptable performance issues - queries that were fine for the large DB and on our other VM’s were taking minutes instead of seconds. Then they’d suddenly (but briefly) be fast.
We could see that the database was hitting its DTU limits due to excessive Data IO, which surprised us. Simply increasing the DTU setting seemed an unsatisfactory solution both because of the cost of operating at that higher setting and the oddness that larger databases we migrated weren’t seeing the same issues.
Reviewing the SQL query plan being used it was clear that the query just wasn’t applying filters where it should and was taking a very memory and disk-intensive approach.
Index Fragmentation Galore
Since the tables in question held a few million rows pretty much every operation had to use indexes effectively or it would suck. We dug back into our normal SQL Server bag of tricks and checked how fragmented the indexes were and found bad news: about half were 99% fragmented. Sitting back and thinking about it this makes some sense as a byproduct of BCP: Since it’s firehosing in records in whatever binary order they were firehosed out with the indexes were being built up in chunks from zero. This means lots of page splits and the index growing essentially randomly. If the migration had added the indexes at the end this would be a non-issue but here we are.
There is some debate as to whether index fragmentation on SQL Azure makes a difference or not. We’ve come down on the side of it being important, particularly if your databases are large. Defragmenting the index can reduce storage space but more importantly should improve query performance, particularly joins that produce sets. We have a stock script we’ve used on SQL Server to roll through a database, review all indexes and rebuild those that are highly fragmented.
The good news is that SQL Azure supports online index rebuilds like SQL Enterprise which means you can do this without blocking inserts and updates. Unfortunately, it will take a serious bite out of your DTUs. Therefore, we run this script on each database before we bring it back online and add it to the pool. We used this Stack Overflow article as a starting point, with limits and other minor adjustments for SQL Azure
SET NOCOUNT ON;
DECLARE @objectid int;
DECLARE @indexid int;
DECLARE @partitioncount bigint;
DECLARE @schemaname nvarchar(130);
DECLARE @objectname nvarchar(130);
DECLARE @indexname nvarchar(130);
DECLARE @partitionnum bigint;
DECLARE @partitions bigint;
DECLARE @frag float;
DECLARE @command nvarchar(4000);
DECLARE @dbid smallint;
-- Conditionally select tables and indexes from the sys.dm_db_index_physical_stats function
-- and convert object and index IDs to names.
SET @dbid = DB_ID();
SELECT
[object_id] AS objectid,
index_id AS indexid,
partition_number AS partitionnum,
avg_fragmentation_in_percent AS frag, page_count
INTO #work_to_do
FROM sys.dm_db_index_physical_stats (@dbid, NULL, NULL , NULL, N'LIMITED')
WHERE avg_fragmentation_in_percent > 45.0 -- Allow some fragmentation
AND index_id > 0 -- Ignore heaps
AND page_count > 25; -- Ignore small tables
-- Declare the cursor for the list of partitions to be processed.
DECLARE partitions CURSOR FOR SELECT objectid,indexid, partitionnum,frag FROM #work_to_do;
-- Open the cursor.
OPEN partitions;
-- Loop through the partitions.
WHILE (1=1)
BEGIN
FETCH NEXT
FROM partitions
INTO @objectid, @indexid, @partitionnum, @frag;
IF @@FETCH_STATUS < 0 BREAK;
SELECT @objectname = QUOTENAME(o.name), @schemaname = QUOTENAME(s.name)
FROM sys.objects AS o JOIN sys.schemas as s ON s.schema_id = o.schema_id
WHERE o.object_id = @objectid;
SELECT @indexname = QUOTENAME(name) FROM sys.indexes WHERE object_id = @objectid AND index_id = @indexid;
SELECT @partitioncount = count (*) FROM sys.partitions WHERE object_id = @objectid AND index_id = @indexid;
SET @command = N'ALTER INDEX ' + @indexname + N' ON ' + @schemaname + N'.' + @objectname + N' REBUILD WITH (ONLINE = ON)';
IF @partitioncount > 1
SET @command = @command + N' PARTITION=' + CAST(@partitionnum AS nvarchar(10));
PRINT CAST(GetDate() as NVARCHAR(60)) + N' - Starting: ' + @command;
EXEC (@command);
PRINT CAST(GetDate() as NVARCHAR(60)) + N' - Completed: ' + @command;
END
-- Close and deallocate the cursor.
CLOSE partitions;
DEALLOCATE partitions;
-- Drop the temporary table.
DROP TABLE #work_to_do;
GO
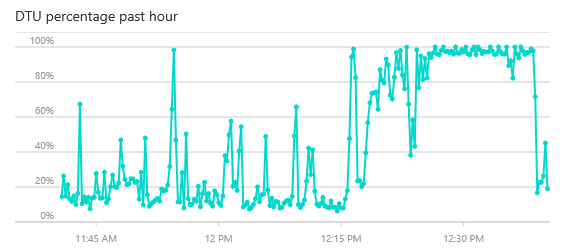 If you’re using SQL elastic pools, be sure you run
this script before moving the database into the pool, it packs a mighty whallop! You’ll notice the right-hand
of the DTU chart reflecting 100% consumption.
If you’re using SQL elastic pools, be sure you run
this script before moving the database into the pool, it packs a mighty whallop! You’ll notice the right-hand
of the DTU chart reflecting 100% consumption.
Unfortunately, in the case of our odd outlier database this still didn’t address the perf problem we saw. We migrated more databases to get more comparables and found that just a few exhibited some very odd, and yet different, query perf issues.
SQL Statistics can Burn You
Ultimately we started asking a different question: Why does one database have a different query plan than five other essentially identical databases? This got us into reviewing how the SQL Query Optimizer creates a plan and picks indexes. One of the biggest inputs it uses are the statistics held on each index and table. These statistics tell the optimizer things like how many rows in an index are likely to match a given key or be null. This information is essential to making good calls on when to use an index and when the index would just be overhead.
You can Update Statistics on a single table or index if you want, or just make a single call to prompt the database to do a check across all its statistics to see if any are likely to need updating.
exec sp_updatestats;
It even produces a pretty good output to see if it really changed things or though they were fine:
Updating [dbo].[Session_Collection_Action]
[IX_Session_Collection_Action_Clust] has been updated...
[PK_Session_Collection_Action] has been updated...
[AK_Session_Collection_Action_Name] has been updated...
3 index(es)/statistic(s) have been updated, 0 did not require update.
Updating [dbo].[Session_Event_Action]
[IX_Session_Event_Action_Clust] has been updated...
[PK_Session_Event_Action], update is not necessary...
[AK_Session_Event_Action_Name] has been updated...
2 index(es)/statistic(s) have been updated, 1 did not require update.
We’ve elected to execute this system stored procedure as part of our standard migration. In the case of our problem queries it appeared to do the trick - the related statistics were rebuilt and suddenly the query plans changed to match the other databases. However, we’ll be on the lookout for other oddly slow queries and see if we need to explicitly force it to rebuild the statistics for any tables. Fortunately, the new SQL Query Performance Insight feature will help us with that (more on this in a future post).
It’ll All Be Worth It In the End
We firmly believe in the vision of database as a service: It just doesn’t make sense for us to be sweating the details of hosting a database engine in a scalable, reliable fashion - that’s a specialized skillset that isn’t directly a value add for our products. That said, while the destination looks like a great place to be, getting there has a lot of bumps along the way. We’ll keep you posted!