Loupe 3.7.3 Maintenance Release Now Available
We’ve just published a new update to Loupe with a number of defect fixes and optimizations. The Loupe SaaS platform has already been upgraded to this release, but Loupe Desktop and on-premises Loupe Servers should upgrade at their next convenient opportunity. This is a free upgrade for all Loupe Desktop users and for any Loupe Server under active maintenance. Download the update now!
Big Scalability Improvements
We operate the largest Loupe installation anywhere for our Software-as-a-Service customers, processing several terabytes of information per day on our largest cluster. As our load has grown we’ve steadily invested in performance and scalability improvements. Some changes are big enough they’re waiting for Loupe 3.8 but we were able to pull several back to this version without an extended risk.
Disk Tuning
We noticed under stress that our back-end file storage system was executing a tremendous volume of requests, most of which were directory information requests not actual data movements. We used Wireshark to do a bit of on-the-wire monitoring of the exact SMB traffic between the web tier and the file servers and discovered that there were several hundred directory information requests for each file transfer. This had us inspecting the exact code we used for a few file operations. In particular, Loupe both creates directories and has to remove directories when they are no longer in use. We do all of this through the managed API and didn’t appreciate the impact of a few choices we made.
Here’s the (very cautious) original code:
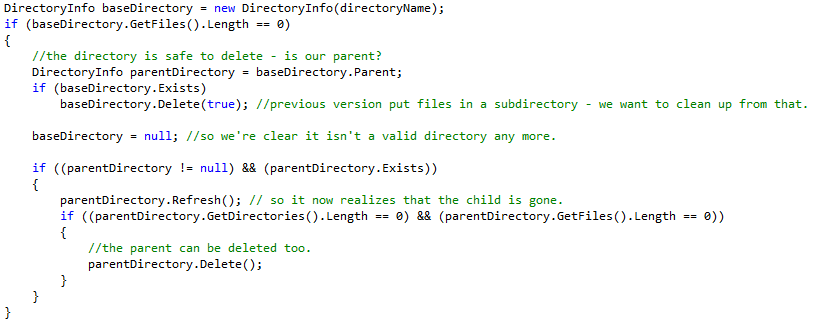
The key problems are first that there isn’t a managed API call to check if something’s empty. Instead, we have to see if we find any files - so it calls GetDirectories and GetFiles. There are two issues - first, they return fully populated detail objects which take multiple server calls to populate. Each. Second, we’re blocking to get the full list of all the files and directories just to see if it’s empty or not before continuing. So not only are the calls quite expensive if there are many files and directories, but we aren’t even using the results. This problem lay hidden for a long time because usually there aren’t a lot of files in the directories we examine and when the code was originally written Loupe didn’t support remote file storage so the question was how much local disk IO this generated - and it’s not nearly as bad.
To fix, this we did three changes. First, we used an alternate call that is stateless and just pulls back the names of entries. This can be done as a single request using the SMB protocol. Second, .NET 4.0 introduced a new method that starts returning data immediately as it enumerates which lets the loop exit as soon as it finds any values, saving extra network calls when there are large sets. Third, we evaluated that the code was too optimistic about testing multiple directories - in actual usage, the higher level directory is the repository folder which would only be empty if there were no session files in the repository. Frankly, that’s not a case to optimize for so we can eliminate it.

Combined with some other cases where we removed some redundant file requests we dropped SMB requests by 95%, leaving the file server to do what it should be spending its time on - pumping bytes in and out to store files.
Database Activity Tuning
Loupe Server uses a SQL Database for tracking session data and for storing all of the information it generates analyzing logs. This creates a few opportunities for SQL Server to be the bottleneck. While analyzing work on our largest cluster we identified several situations where performance could be improved:
- Tracking Sessions for Download: Whenever a computer contacts the server, the server has to calculate what sessions to let it download. This uses the list of all sessions ever received from that computer, causing it to slow down for computers that send a large number of sessions.
- Over-aggressive Status Refresh: A simple coding error prevented it from ever caching the configured information for a server, causing it to fetch it from the database every time (potentially several of times for every server request). This was a cheap action, but the high number of occurrences could mask other useful work.
- Assigning Sessions Versions: Every time a session is changed a new version number is assigned. These are granted as requested with each change getting the next sequential version number. This limits the number of changes on a server to how fast the version can be incremented and stored again. While this is pretty fast, this creates a limit of about 50-200 changes per second depending on the performance of the storage system.
We’ve fixed the second and third items. For assigning session versions we rewrote the system so it would assign at most one version number per second and wouldn’t expose that version number to any clients for a following two seconds. This ensures clients can correctly assume if they see a version number all changes through that number are included but we no longer have a limit on the number of changes per second.
For a real world picture on the effect of these changes, look at the traffic chart for one of our production SaaS clusters. See if you can spot when we upgraded it to 3.7.3:
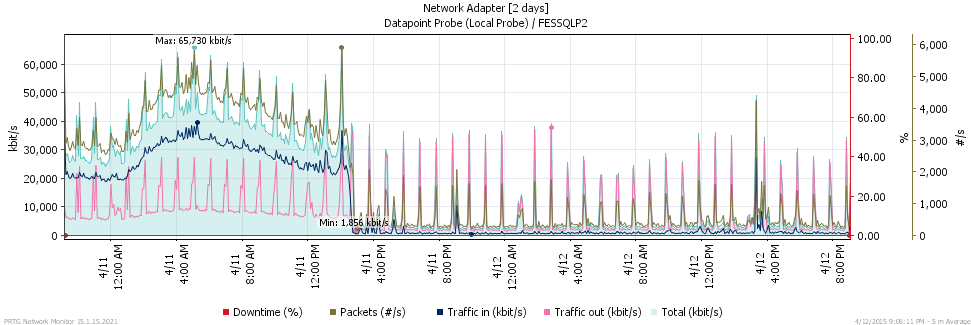
The results were even better than we expected; we spent several hours after deployment going back and forth to prove that there wasn’t a defect preventing us from receiving or processing data. But, we were able to verify standard data volumes from other sources and ultimately determined that the defect related to retrieving server status was even worse than we previously expected.
Active Directory Enhancements
While working with our first few customers that implemented AD integration we spotted some odd results. Digging into them, we eventually realized that we had to be much more careful about assumptions we (and the .NET API) made about data integrity in Active Directory. Many large companies do updates to AD from several sources, and not all sources respect the same rules. Consequently, things the API says can be counted on to be unique (like User Principle Name) well.. aren’t. We took a few steps back and made Loupe much more suspicious of the data from AD so that it would give predictable, good results even in the case of some odd situations.
We’ve modified it to build its own version of the UPN from the fragments in AD and to explicitly probe when authenticating for the alternate names people expect. The result is that even if the AD breaks some of the conventions you can still authenticate using the name forms people expect, including just their short user name without domain.
Defect Fixes All Around
We use Loupe ourselves to monitor our products. This release includes 13 fixes that were never explicitly reported by customers but showed up by using the Manage Issues page of our own Loupe Server. We did this work using the soon-to-be-released first beta of Loupe 3.8 as a real-world usability test that did its job - we’re going to hold that beta to fix a few things we saw.
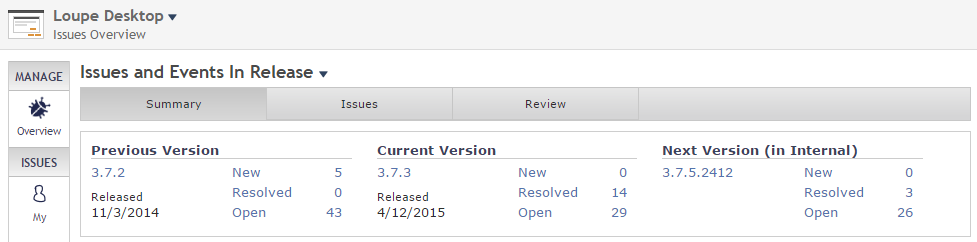
As you can see, we addressed 14 runtime issues in 3.73 and we’ve got a further 3 queued up for Loupe 3.8 (they were not easily retrofitable to 3.7). We’ll go after another batch of these before 3.8 is released.
For a full list of fixes and changes, see the release notes for Loupe 3.7.3.
Up Next - Loupe 3.8 Beta 1
We’re putting the final touches on the first beta of Loupe 3.8. Once we’re confident it’s ready for real world use and it’s good enough to get valuable feedback we’ll be posting it. Depending on customer feedback we plan on shipping the final release in 6-8 weeks.