Implementing SQL Elastic Pools for affordable SQL Azure databases
Like many SaaS systems, Loupe uses a database-per-tenant model. There are a number of reasons for this design choice, but it has created a big problem for us in migrating to SQL Azure: It was simply unaffordable due to the per-database pricing model. Our testing indicated we needed at least 50 DTU to run a medium-sized Loupe installation which would cost $75 per month for each repository. I’m not sure if you’ve looked at our pricing recently, but we start at $25 and even at our Professional tier that’d be 50% of our total revenue just for a modest database.
Starting last August, Microsoft debuted SQL Elastic Pools. The basic idea with an Elastic Pool is that performance and storage limits can be shared by a number of databases. For example, you can create a 100 DTU pool and put 200 databases with a total storage of 200GB. The various databases then compete with each other to use capacity up to the 100 DTU limit. It’s very similar to having a dedicated server, but with the ability to scale the pool on demand and no servers to maintain.
It’s Like Your Own Server
Pricing for Elastic Pools are reasonable, at least when compared to SQL Azure. Effectively, each DTU of capacity costs 150% what it would for a single database. Since pools are more likely to use their full storage and DTU capacity they would cost more to host. A Standard 200 eDTU pool is cheaper than setting up a SQL Server VM with similar throughput (even using SQL Web Edition). The story for Premium pools is not nearly so good. Like SQL Azure, the price jump from Standard to Premium is eye watering. For example, a 100 eDTU standard pool is $225 per month while a 125 eDTU Premium pool is nearly $700. For us this price jump is dramatic - You could easily *beat* the performance at a lower price point setting up a SQL Server VM.
Balancing work is quite easy - you can move a database between pools and out of a pool fairly quickly. There is a minor disruption when a database is moved (all connections are dropped) but if you’re ready for SQL Azure you have to be ready for that anyway. We took advantage of this feature during the migration - we initially migrated to standalone databases and once we’d imported and optimized the database we moved it into the pool. This let us use higher performance settings during the migration to reduce migration time and ensured the migration didn’t monopolize the pool. We were able to run several migrations in parallel without impacting migrated customers.
We initially created a Standard pool with 100 eDTU. Unfortunately, we were getting too many requests rejected due to no capacity available because any one database could monopolize the pool. Microsoft has also provided some basic ways to reduce the “noisy neighbor” problem with shared hosting: You can limit the maximum performance a single database can access at a time (but only with very coarse settings) and you can reserve capacity for all databases, but at the risk of severely limiting the number of databases in the pool. The smallest limit that can be set is 100 eDTU so we needed to up our pool size to 200 eDTU to start taking advantage of this.
We would have liked to take advantage of reserving capacity for databases but at the smallest setting - 10 DTU - You can only have 20 databases at the 200 eDTU pool setting, and each would basically run as a 10 DTU database. This would be an expensive, and slow, configuration. Fortunately, by limiting ourselves to about 50 databases we found that just setting the per-database maximum to 100 eDTU eliminated the competition problem between our own databases.
Premium and Standard DTU’s Aren’t the Same
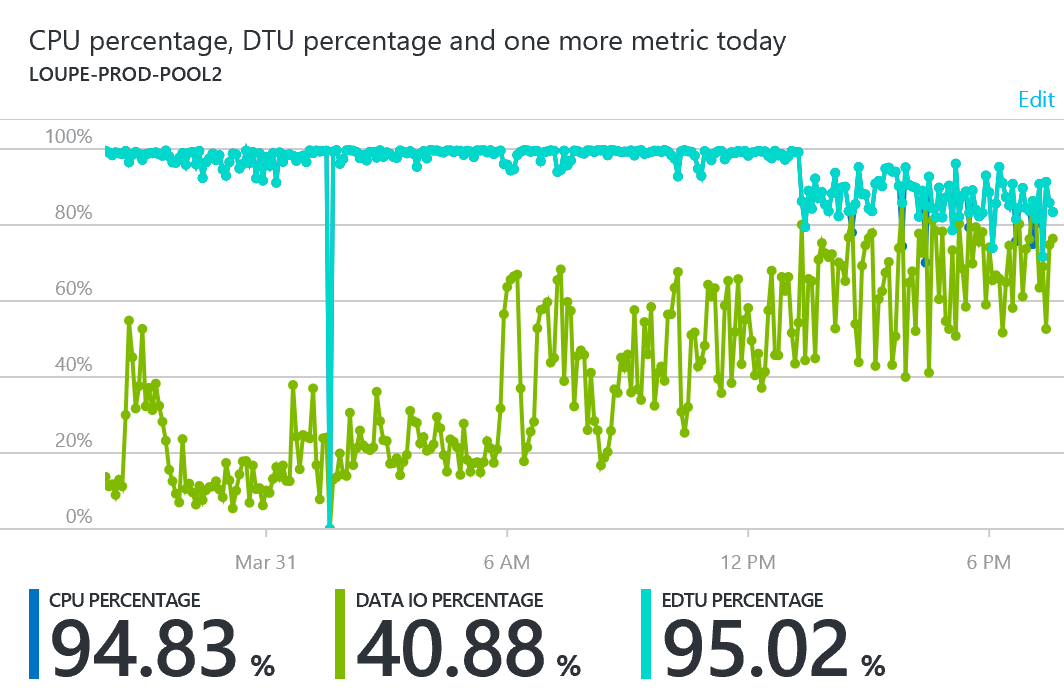
Premium Pools load balance nicely, letting you run them at maximum capacity
One thing we discovered over the first month of running in this configuration is we were having a very difficult time getting reasonable performance across the whole system even though our pool showed only about 65% utilization on a minute-by-minute basis. It was a bit tricky to analyze the reasons behind this because SQL Azure doesn’t support the low-level memory and disk counters that would distinguish queries pounding disk due to inadequate memory vs. general IO performance. Working with Microsoft, we ultimately added a second 125 DTU premium pool and moved our high activity customers into it. Once the migration completed (this can take a while depending on database size) we saw notable improvement in performance. In general we saw performance much closer to a VM with SSD’s than what we saw with the Standard pool. Even with the pool using 100% of its DTU each database was responsive. We’re getting results at least four times faster under Premium. Still, paying $5.60 per DTU is a painful step up from $2.25. I’d like to see a price closer to $4.00 as reasonable.
Opportunities to Improve Elastic Pools
We’d like to see a much smarter routine for reserving capacity - instead of reserving a fixed amount for each database use a model where it works to keep a small amount of capacity free for the next request so it can handle swings in load without rejecting activities. This would be similar to how Windows manages memory (and most shared systems manage performance).
Elastic Jobs: Lotsa potential, but…
The elastic jobs feature shows a lot of potential but has two key shortcomings currently: First, it requires provisioning an explicit database and virtual server to host the job system (which you have to pay for). This creates more complexity and cost for a feature that’d ideally just be rolled into the elastic pool pricing and setup. It stands out as an oddly manual feature in an otherwise nice service. Second, the portal needs to be enhanced to provide access to scheduling jobs and deleting completed jobs. This feature is aimed squarely at DBA’s, but this group is extremely unlikely to break out PowerShell.
The other problem we’ve had with elastic jobs is there isn’t a mechanism to limit the parallelism. For example, say you were going to implement one of the standard SQL Server maintenance jobs - like updating statistics on the database. This uses DTU capacity to run, but if you create an elastic job to do this it’ll start on all databases at the same time, effectively monopolizing the pool. The first time we did this it basically took down the entire pool for 15 minutes. Instead, the elastic pool should let us set a maximum number of parallel databases to run the job on at the same time so we can be sure it doesn’t block routine load.