Developing Loupe 4 - Web UI Architecture and Technology
The Backstage Pass articles so far have tended to focus on features; discussions with customers, ideas and wireframes. We thought it was time to share the architecture and technology of the Loupe Server web application, looking at the current architecture, and what the future holds for the development team.
Current Architecture
The current architecture of Loupe Server is rooted in ASP.NET MVC, but is not a pure MVC application, nor is it a Single Page Application (SPA). Instead it’s a combination of the two, with major areas requiring a full page load, while pages within an area being SPA based, using Path for routing. Even then, the SPA aspect is not fully client side, as the user interface is dynamically loaded MVC Razor views, using Razor’s server-side rendering. Client side interaction is handled via Knockout, with the Razor model mapped to JavaScript (using the Knockout mapping plugin) models in each view. UI components are handled either with jQuery UI or Kendo (the grids and charts in particular). The backend is pure MVC controllers and models, backed onto our server project that exposes shared functionality and the data access (EF).
Intrinsically, there is nothing wrong with this architecture per se, nor with any of the technologies involved; it meets our current needs and performs well. But as Loupe grows and more features are added, we notice that some areas could be improved, such as:
- Obsolete Code. Some existing code was written to cater for lack of functionality in MVC, such as injection, bootstrapping and JSON serialisation. This now exists in MVC, and while there is no immediate requirement to replace our custom code, it’s code we have to maintain.
- Repeated Code. Since this is an MVC application, each View has an associated Model, which is sometimes required as a JavaScript model; not always, as some views are pure MVC. For those that require client interaction, the Knockout plugin takes care of mapping the server model to JavaScript, but we now end up with two models, and more code than we really want.
- Back Button and Deep Linking. With a hybrid SPA application, routing needs to be configured for server views and client navigation. For Loupe this leads to some issues with the back button and deep linking, both of which are key to some of our future features.
- User Experience. The hybrid nature of Loupe is generally not a problem, but as our features improve and increase, the navigation structure starts to become a blocking point. For example, take a workflow of dealing with Issues, where you may need to drilldown into Sessions and Logs, then navigate back to the Issues. Features planned in Loupe 3.8 provide a much more structured approach to finding data, but building effective transitions in the current architecture is problematic. You’ll see more about this navigation idea in future posts as we release more wireframes.
- Loupe Server and Desktop Parity. In a previous post, we talked about feature parity between the Web and Desktop versions of Loupe. If more features are to be shared, we need to ensure that a common code base is used for those shared features.
- Library Upgrades. Some of our client libraries are linked by version dependencies, so upgrading one requires upgrading another, and so on. With inter-dependencies, upgrades become problematic and time consuming.
For a product that’s grown organically over the last few years, we’re happy with what we have. But as we planned more features, we realised some of these problems would hinder us, not only in terms of what could be delivered, but also the cost of delivery.
Moving Forward
The ideal solution is a rewrite, but that comes at a cost. For a start there would be the time lost in just getting back to feature parity before new features could be considered. Would a rewritten architecture provide for the product’s future needs? More importantly, would the customers be getting a better product and experience? Could we just achieve the same result by progressive enhancement?
We spent a long time debating these, but ultimately decided a rewrite was worth the cost. Here’s why:
- User Experience. We can move to a full SPA architecture. While SPA’s seem like a bandwagon to jump on, we’ve seen we can provide a better user experience this way.
- UI Features. We can more easily achieve the UI we have planned than in the current code base.
- Code Cleanup.
- Code Sharing. We can remove repeated code and provide a better mechanism for sharing code between products.
- Maintainability. Future maintenance will also be improved by refactoring the existing code.
- Encapsulation. Better separation of UI from implementation.
- Unified Codebase. Progressive enhancement would lead to a split codebase, worsening the maintenance problem.
- Improved speed of feature implementation. With a cleaner architecture and better split between UI and functionality, new features can be implemented more easily than the existing code.
- Past Experience. We’ve built SPA products for clients and the experience for both them and us has been good.
- Developer Happiness. It may seem a small point, but the better code is to work with, the happier developers are.
Having decided that we were going to rewrite, the next question was what technology were we going to use?
Building the Product
 The technology we chose had to rely on our development teams skills, as a rewrite would be expensive enough without learning new technology. There are several SPA frameworks, all with pros and cons, but we’d just completed a successful client project built with ASP.NET Web API and Angular, so this seemed an obvious choice. We’ve ignored the current schism in the Angular world for the simple reason that the Angular 1.x branch provides most of what we need from a SPA framework. Angular 2 won’t be shipped until late 2015 and some of the features proposed seem less than perfect (the binding syntax for example). It’s unlikely we’d consider upgrading from 1.x to 2.0 unless there were significant benefits.
The technology we chose had to rely on our development teams skills, as a rewrite would be expensive enough without learning new technology. There are several SPA frameworks, all with pros and cons, but we’d just completed a successful client project built with ASP.NET Web API and Angular, so this seemed an obvious choice. We’ve ignored the current schism in the Angular world for the simple reason that the Angular 1.x branch provides most of what we need from a SPA framework. Angular 2 won’t be shipped until late 2015 and some of the features proposed seem less than perfect (the binding syntax for example). It’s unlikely we’d consider upgrading from 1.x to 2.0 unless there were significant benefits.
Scripts and Project Structure
One aim of the rewrite was to remove the hodgepodge of scripts used to provide features, but we’ve not eschewed external scripts, far from it. We’re just using more built-in features where possible and adding on where needed. For example, instead of the built-in routing, we’re using UI-Router as it provides a richer feature set for routing, along with UI-Router-Extras, for some additional state handling. Additional Angular modules for dynamic script loading, cookie and local storage, and dialogs are also used.
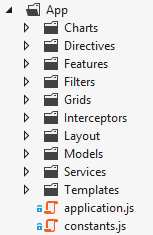 Structurally, we’re using a fairly standard layout for the project, with the client application code held under an App folder. Learning from a previous project, we keep the controllers and views together, under feature folders in Features, making it easy to work on functionality without moving folders. Library code, including Angular itself, is hosted in the site Scripts folder, and updated via nuget.
Structurally, we’re using a fairly standard layout for the project, with the client application code held under an App folder. Learning from a previous project, we keep the controllers and views together, under feature folders in Features, making it easy to work on functionality without moving folders. Library code, including Angular itself, is hosted in the site Scripts folder, and updated via nuget.
For UI components we’ve stuck with Kendo, especially now they have built-in support for Angular. While not perfect, it’s getting better with each release and provides good interaction between the Angular and Kendo frameworks. We’ve rewritten some of our custom scripts that centralised handling of Kendo’s grids and charts, converting them into Angular services and directives to wrap our own requirements.
Backend
At the backend, most of the functionality in the MVC controllers has ported fairly simply over to WebAPI controllers, now returning JSON instead of MVC views. This has reduced a large amount of code from the controllers, since they are now only concerned with data; there are no methods to load views since this is all handled client-side. In the future we’ll be slimming these down even more as we share more functionality between the products. We’ve also reduced the number of explicit model classes, using anonymous types for return data if no model is required. For this reason we’re no longer using AutoMapper; while AutoMapper reduces the amount of code written, we decided the trade-off worth it; it may mean more code to write (constructing the anonymous type), but the code is more explicit, more developer friendly (you don’t have to look at the mapping to see how the data is constructed), and faster.
Infrastructure
For builds, we’ve done a small development change, switching from Cassette to MVC’s built in bundling. While this is an SPA, we do have a single MVC view that provides the central layout and a place to include the bundles. We’ve kept most of the existing CSS, deciding that switching to a richer framework such as SASS or LESS wasn’t worth the effort. The build server is Team City based.
One major change, long overdue, is the move from TFS to Git. We’ll have another post later about this decision and what the switch brings us.
Was it worth it?
Time will tell, but initial views seem to be that Loupe has a snappier feel and is faster. From a developer’s perspective, the code base is much improved, making it easier to add features and maintain the ones we have.
I Like What You’re Doing But…
Or you hate what we’re doing because we missed something important? Please - let us know. How? Well - could be in the comments below, or if you want to have your feedback be private submit it through the support portal.
Up Next: Wireframes and walkthroughs of Event Matching Rules, a totally new feature for Loupe 4.
Get Your Backstage Pass
Subscribe below to receive additional Loupe 4 updates, design artifacts, previews builds and special offers.